
Release notes for Groovy 5.0
Groovy 5 builds upon existing features of earlier versions of Groovy. In addition, it incorporates numerous new features and streamlines various legacy aspects of the Groovy codebase.
|
Additional Scripting Variations
JEP 512, targeted for JDK25
(and previewed in earlier JDKs:
JEP 445
JEP 463
JEP 477
JEP 495
),
introduces a new main method signature and compact source notation for Java classes.
Groovy 5 supports this new notation, as well as Groovy’s traditional scripts,
and an alternative abbreviated form.
Let’s recap the story so far. First, a traditional (Java) class:
public class HelloWorld { // Java (also Groovy)
public static void main(String[] args) {
System.out.println("Hello, World!");
}
}Second, a traditional Groovy script:
println 'Hello, World!'Groovy scripts are given implicit main and run methods and an implicit class definition.
Variable declarations in scripts are local variable declarations in the implicit run method
unless annotated with @Field, in which case they become field definitions of the implicit class.
Third, the "instance main" method proposed for JEP 512 in Java with an implicit class definition:
void main() { // Java JDK25 (also Groovy 5+)
IO.println("Hello, World!");
}Variants with arguments are also supported as are "static main" methods.
Groovy supports such methods on JDK11+ and supports some slight simplifications:
def main() {
println 'Hello, World!'
}Finally, Groovy also provides an "instance run" method as an alternative form:
def run() {
println 'Hello, World!'
}You may wonder why Groovy supports the JEP 512 notation when the traditional Groovy script is shorter? Firstly, there is Java compatibility, but also there are scenarios where we might like to use method or class annotations, and that is hard to do for an implicit method or an implicit class.
TYPE targeted annotations on the main or run method will be moved to the generated
script class. METHOD targeted annotations remain on the method.
Classes created with an "instance main" method (like above) are JEP 512 compatible classes and will need to be invoked from the JDK with JEP 512 capability enabled or using the Groovy runner which now supports such classes from JDK11+.
For backwards compatibility, classes created with a static main method are
promoted to have the normal public static void main signature. They can be run
like normal Java or Groovy classes.
There are variants in Java and Groovy to also have arguments available:
@CompileStatic
static main(args) {
println 'Groovy world!'
}JEP 512 compatible classes may also contain other field and method definitions as shown here:
def main() {
assert upper(foo) + lower(bar) == 'FOObar'
}
def upper(s) { s.toUpperCase() }
def lower = String::toLowerCase
def (foo, bar) = ['Foo', 'Bar']But they can’t contain any other "uncontained" statements, otherwise they
are treated like a normal Groovy script. Another important distinction for JEP 512
compatible classes is that fields (like lower, foo, and bar in the above example)
don’t need to be annotated with @Field.
An additional form is also supported which involves supplying a run method
instead of a main method.
This provides an alternate form to the earlier shown main variants.
The difference is that rather than producing a JEP 512 compatible class, Groovy
produces a script class which extends the Script class in the normal way and has
access to the normal script binding and context. The use case is again where you
might want to supply annotations, e.g.:
@JsonIgnoreProperties(["binding"])
def run() {
var mapper = new ObjectMapper()
assert mapper.writeValueAsString(this) == '{"pets":["cat","dog"]}'
}
public pets = ['cat', 'dog']To summarise:
-
If you need access to the script binding or context, write a traditional class that extends the
Scriptclass, or a traditional Groovy script, or use therunmethod. -
If you use the supported
mainorrunmethod variants, you can have field definitions and other methods, and you don’t need@Field. Consider these if you don’t like@Fieldor you want to use annotations on the implicit class or the main/run method. -
If your source file has any statements outside methods that aren’t field declarations, it will be treated as a traditional Groovy script.
-
Use the "instance main" method variant if you want the generated bytecode to follow JEP 512 conventions. You will need JDK25+ to run from Java, or JDK11+ to run from Groovy.
Improved Web Content Creation
Jakarta EE support
The groovy-servlet module supports:
-
Writing servlets as Groovy scripts (Groovlets), e.g.:
html.html { head { title 'My first Groovlet' } body { h1 'Welcome to Groovlets!' } } -
Writing servlets as Groovy classes (typically extending
AbstractHttpServlet) -
Writing Template-style, JSP-like Groovy Server Pages which combine (typically) HTML with Groovy control-logic within special tags
Groovy 5 defaults to Jakarta EE versions of the Servlet-related standards. This mostly involves using versions of the underlying classes with different package names.
When writing Groovlets or GSPs, the change in package name might not be apparent, since for simple examples, like the one shown above, the package names don’t appear, but the underlying classes being used would change. If you are using Groovylets, your transition to Jakarta EE should be a little easier.
You can still obtain the older Javax EE versions of the relevant classes using
the "javax" classifier when specifying your dependency on groovy-servlet.
Improved Type Checking
Groovy’s type checking is extensible. This allows you to weaken or strengthen type checking. In Groovy 5, we’ve added a type checker for format strings. Errors in such strings are often not detected until runtime, but now you can check them at compile time. It adds to the existing regex checking capabilities.
An Optional Type Checker for Format Strings
The format methods in java.util.Formatter, and other similar methods,
support formatted printing in the style of C’s printf method with a
format string and zero or more arguments.
Let’s consider an example which produces a string comprised of three terms:
-
a floating-point representation (
%f) of PI (with 2 decimal places of precision), -
the hex representation (
%X) of 15 (as two uppercase digits with a leading 0), -
and the Boolean (
%B)True(in uppercase).
The assertion checks our expectations:
assert String.format('%4.2f %02X %B', Math.PI, 15, true) == '3.14 0F TRUE'This is a powerful method supporting numerous conversions and flags. If the developer supplies incorrect conversions or flags, they will receive one of numerous possible runtime errors. As examples, consider the following mistakes and resulting runtime exceptions:
-
supplying a String as the parameter for either of the first two arguments results in an
IllegalFormatConversionException, -
leaving out the last argument results in a
MissingFormatArgumentException, -
supplying the leading zero flag for the Boolean parameter results in a
FlagsConversionMismatchException.
The goal of the FormatStringChecker is to eliminate
a large number of such runtime errors. If the API call passes type checking,
it will be guaranteed to succeed at runtime.
AST transform additions and improvements
Making Operators More Groovy
There is a new OperatorRename AST transform.
This is very useful when using third-party libraries which use different
names to those used by Groovy’s operator overloading functionality.
For example, using the Apache Commons Numbers Fraction library:
@OperatorRename(plus='add')
def testAddOfTwoFractions() {
var half = Fraction.of(1, 2)
var third = Fraction.of(1, 3)
assert half.add(third) == Fraction.of(5, 6) // old style still works
assert half + third == Fraction.of(5, 6) // fraction '+' operator!
}This transform is quite handy when using various matrix packages. Such packages often align with Groovy’s operator overloading conventions for many, but usually not all, operators. For instance, you might like to rename:
-
multtomultiplyif using Ejml -
addtoplusif using Commons Math matrices -
subtominusif using Nd4j matrices
Groovy has excellent support for writing Domain Specific Languages (DSLs),
but using the @OperatorRename transform means we can skip constructing our own DSL in simple cases.
Extension method additions and improvements
Groovy provides over 2000 extension methods to 150+ JDK classes to enhance JDK functionality, with 350 new methods added in Groovy 5. These methods reduce dependency on third-party libraries for common tasks, and make code more intuitive. Let’s explore some highlights from those 350 new methods.
Additional Collection extensions
The repeat method repeats the elements in a collection a certain number of times, or infinitely.
The finite variant is an alias for multiply, the '*' operator.
def words = ['row'].repeat(3) + ['your', 'boat']
assert words.join(' ') == 'row row row your boat'
def batman = ['na'].repeat().take(13).join('-') + '...Batman'
assert batman == 'na-na-na-na-na-na-na-na-na-na-na-na-na...Batman'The zip method creates tuples from elements of two collections, grouping elements with the same index.
In the case of differing size collections, the number of tuples created will be
equal to the size of the shorter of the two collections.
The zipAll method provides a way to handle collections of different sizes, giving
default values in that case.
The number of tuples created will be
equal to the size of the longer of the two collections.
def one = ['🍎'].repeat(4)
def two = ['🍏'].repeat(3)
assert one.zip(two).toString() == '[[🍎, 🍏], [🍎, 🍏], [🍎, 🍏]]'
assert two.zip(one).toString() == '[[🍏, 🍎], [🍏, 🍎], [🍏, 🍎]]'
assert one.zipAll(two, '_', '🍌')*.join() == ['🍎🍏', '🍎🍏', '🍎🍏', '🍎🍌']
assert two.zipAll(one, '🍊', '_')*.join() == ['🍏🍎', '🍏🍎', '🍏🍎', '🍊🍎']The interleave method interleaves the elements from two collections.
If the collections are of different sizes, interleaving will stop once one
of the collections has no more elements. An optional boolean parameter allows the remaining
elements of the longer collection to be appended to the end of the result.
When the collections are the same size, the same result could be achieved by zipping
the collections and then flattening the result, but interleave is more efficient
and provides options for handling the case when the collections are different sizes.
def gs = ['🅶'].repeat(5)
def hs = ['💚'].repeat(3)
assert gs.interleave(hs).join() == '🅶💚🅶💚🅶💚'
assert hs.interleave(gs, true).join() == '💚🅶💚🅶💚🅶🅶🅶'The flattenMany method is a close cousin to the
collectMany method. These are Groovy’s flatMap-like methods.
var items = ["1", "2", "foo", "3", "bar"]
var toInt = s -> s.number ? Optional.of(s.toInteger()) : Optional.empty()
assert items.flattenMany(toInt) == [1, 2, 3]
assert items.flattenMany(String::toList) == ['1', '2', 'f', 'o', 'o', '3', 'b', 'a', 'r']
assert items.flattenMany{ it.split(/[aeiou]/) } == ['1', '2', 'f', '3', 'b', 'r']
assert ['01/02/99', '12/12/23'].flattenMany{ it.split('/') } ==
['01', '02', '99', '12', '12', '23']If you are working solely with collections, using collectMany will offer
improved type inference with type checked code. If you also want to
flat other things like arrays and optionals, flattenMany gives some
added flexibility.
There are additional variants of collectEntries for arrays, iterables and iterators
with separate functions for transforming the keys and values. There are variants
with and without collectors.
There are also variants which transform just the key or value.
The withCollectedKeys method collects key/value pairs for each item with the
item as the value and the key being the item transformed by the supplied function.
The withCollectedValues method collects key/value pairs for each item with the
item as the key and the value being the item transformed by the supplied function.
def languages = ['Groovy', 'Java', 'Kotlin', 'Scala']
def collector = [clojure:7]
assert languages.collectEntries(collector, String::toLowerCase, String::size) ==
[clojure:7, groovy:6, java:4, kotlin:6, scala:5]
assert languages.withCollectedKeys(s -> s.take(1)) ==
[G:'Groovy', J:'Java', K:'Kotlin', S:'Scala']
assert languages.withCollectedValues(s -> s.size()) ==
[Groovy:6, Java:4, Kotlin:6, Scala:5]There are also equivalent variants for maps. The collectEntries method
takes separate functions for transforming the keys and values.
The collectKeys and collectValues variants take a single function
for transforming just the keys and values respectively.
def lengths = [Groovy:6, Java:4, Kotlin:6, Scala:5]
assert lengths.collectEntries(String::toLowerCase, { it ** 2 }) ==
[groovy:36, java:16, kotlin:36, scala:25]
assert lengths.collectKeys{ it[0] } == [G:6, J:4, K:6, S:5]
assert lengths.collectValues(Math.&pow.rcurry(2)) ==
[Groovy:36.0, Java:16.0, Kotlin:36.0, Scala:25.0]
assert lengths.collectValues(Math.&pow.curry(2).memoize()) ==
[Groovy:64.0, Java:16.0, Kotlin:64.0, Scala:32.0]There are a number of new extensions for Sets including operator overload variants:
var a = [1, 2, 3] as Set
var b = [2, 3, 4] as Set
assert a.union(b) == [1, 2, 3, 4] as Set
assert a.intersect(b) == [2, 3] as Set
assert (a | b) == [1, 2, 3, 4] as Set
assert (a & b) == [2, 3] as Set
assert (a ^ b) == [1, 4] as Set
Set d = ['a', 'B', 'c']
Set e = ['A', 'b', 'D']
assert d.and(e, String.CASE_INSENSITIVE_ORDER) == ['a', 'B'] as Set
assert e.union(d, String.CASE_INSENSITIVE_ORDER) == ['A', 'b', 'D', 'c'] as SetThe injectAll method is like inject but collects intermediate results.
This is like the scan gatherer in JDK24 or the prefix scan operation in Arrays#parallelPrefix.
def letters = 'a'..'d'
assert ['a', 'ab', 'abc', 'abcd'] == letters.injectAll('', String::plus)
assert ['a', 'ab', 'abc', 'abcd'] == letters.stream().gather(Gatherers.scan(()->'', String::plus)).toList() // JDK24+
Integer[] nums = 1..4
Arrays.parallelPrefix(nums, Integer::plus)
assert [1, 3, 6, 10] == nums
assert [1, 3, 6, 10] == (1..4).injectAll(0, Integer::plus)The partitionPoint method is used when processing partitioned (often sorted) collections.
You can use it to find the first and last index of a partition in a collection.
For a sorted collection, this would tell you where you could insert a new element and maintain
sorted ordering.
def nums = [0, 1, 1, 3, 4, 4, 4, 5, 7, 9]
def lower = nums.partitionPoint{ it < 4 }
def upper = nums.partitionPoint{ it <= 4 }
assert [lower, upper] == [4, 7]
nums.indices.every {
it in lower..<upper ==> nums[it] == 4
}The JDK’s List#subList method is very handy for working with mutating methods from the JDK Collections API
on part of a list. Groovy 5, now offers a version of that method taking a range.
def fruit = ['🍏', '🍎', '🍉', '🍋', '🍇']
def apples = fruit.subList(0..<2)
assert apples == ['🍏', '🍎']
apples.clear()
assert fruit == ['🍉', '🍋', '🍇']A known feature of some queues within the JDK Collections API,
is that the standard iterator for queues like PriorityQueue don’t return elements in priority order.
Instead, the poll() method is used to return the next highest priority element.
The drain method provides an easy way to poll all the elements from a queue.
def letters = new PriorityQueue(String.CASE_INSENSITIVE_ORDER)
letters.addAll(['Z', 'y', 'X', 'a', 'B', 'c'])
assert letters.toList() == ['a', 'B', 'c', 'Z', 'X', 'y'] // uses iterator()
assert letters.drain() == ['a', 'B', 'c', 'X', 'y', 'Z']
assert letters.emptyChecked collections
Java, being statically typed, tries hard to ensure type safety at compile time
but provides some flexibility to work with objects whose type can only be
checked at runtime. Because of type erasure, Java’s runtime checking is curtailed
to some degree. It is not unusual for errant programs to fail, e.g. with a ClassCastException. The issue is the failure may occur
a long way from the part of the code which caused the problem. The CheckedXXX
classes within java.util.Collections provide a way to improve type safety and
find such issues at the origin of the problem. When debugging errant code,
one recommendation is to wrap your collections with the checked classes.
Once the error is found and fixed, remove the wrapping code for better performance.
Code using Groovy’s dynamic
nature can be even more lenient than Java code, so Groovy can benefit from these
classes even more than Java, so we made them easy to use with an asChecked
method added for the common collection types.
// assume type checking turned off
List<String> names = ['john', 'pete']
names << 'mary' // ok
names << 35 // danger! but unnoticed at this point
println names*.toUpperCase() // fails hereIn this example, we could turn type checking on for immediate feedback
but in general we might be using a library with less information available
due to type erasure. In any case, we can use asChecked to fail early:
// assume type checking turned off
List<String> names = ['john', 'pete'].asChecked(String)
names << 'mary' // ok
names << 35 // boom! fails earlyThe asChecked methods add to the existing asImmutable, asUnmodifiable, and asSynchronized methods.
Iterator extension method improvements
The JDK stream API provides excellent functionality for working with streams of data. It works really nicely with Groovy, but Groovy also offers a rich set of extension methods on Iterators as an alternative approach for processing streams of data. The following Iterator extension methods were added or improved for Groovy 5:
chop, collate, collect, collecting, collectEntries, collectingEntries, collectMany, collectingMany, countBy, findingAll, findIndexValues, findingResults, flatten, flattenMany, injectAll,
interleave, join, plus, repeat, tapEvery, withCollectedKeys, withCollectedValues, zip, and zipAll.
We have seen some of these before, but the variants ending in "ing"
might look slightly different and some explanation is useful.
The streams API makes the distinction between intermediate and terminal operations.
The rough equivalent for Iterator methods is that methods with an Iterator return type are a little
like intermediate operations, and methods with a non-Iterator return type are a little like terminal operations.
There are many of both types in the iterator extension methods.
Methods like drop, takeWhile, withIndex, and unique all return Iterators (i.e. a stream of data).
Whereas count, inject, max, every, any, find, and findIndexOf all return simple numbers or booleans.
For historical reasons, there are some methods which return a List. There are times when you want the whole
list and other times when lazy Iterator processing is more appropriate. For most methods on Iterators,
we return Iterators, and you can call toList() to get the whole list if you want it.
But for backwards-compatibility of a handful of long-standing methods,
Groovy provides both eager and lazy variants:
| Eager | Lazy |
|---|---|
collect |
collecting |
collectEntries |
collectingEntries |
collectMany |
collectingMany |
findAll |
findingAll |
findResults |
findingResults |
The lazy variants are necessary when working with infinite streams of data and, like streams, will be more efficient in scenarios where lots of processing might be needed, but an early return is also possible.
As an example, here is an eager example which uses a few hundred Mb of memory and takes a couple of minutes to run:
assert (0..1000000)
.collect(n -> 1..n) // [1..1, 1..2, 1..3, ...]
.collect(r -> r.sum()) // [1, 3, 6, 10, ...]
.collate(2) // [[1, 3], [6, 10], ...]
.collect{ a, b -> a * b } // [3, 60, 315, ...]
.findAll{ it % 2 } // [3, 315, ...]
.take(3) == [3, 315, 2475]On the same machine, the lazy version uses a few hundred Kb of memory and takes a few 10s of milliseconds to run:
assert (1..100000).iterator()
.collecting(n -> 1..n) // [1..1, 1..2, 1..3, ...]
.collecting(r -> r.sum()) // [1, 3, 6, 10, ...]
.collate(2) // [[1, 3], [6, 10], ...]
.collecting{ a, b -> a * b } // [3, 60, 315, ...]
.findingAll{ it % 2 } // [3, 315, ...]
.take(3)
.toList() == [3, 315, 2475]You can also switch readily between the stream and iterator APIs:
assert (1..100000).iterator()
.collecting(n -> 1..n)
.stream()
.map(r -> r.sum())
.iterator()
.collate(2)
.collecting{ a, b -> a * b }
.stream()
.filter{ it % 2 }
.limit(3)
.toList() == [3, 315, 2475]|
Note
|
A desirable property of Groovy’s extension methods is that
the series of calls needed for performing a series of operations
is the same regardless of whether arrays, iterables, or iterators
are being used. That currently isn’t the case for the 5 methods
mentioned above for the case where you want iterator return types
for subsequent calls. This might sound like a flaw, but it’s more like
the case where for Java streams, some custom functionality could be
implemented using either intermediate (Gatherer) or terminal (Collector) operators. Having said that, a future release of Groovy may improve this situation. It might provide aliases, like map for collect,
filter for findAll, etc. Alternatively, it might provide methods like
collecting for iterables and arrays. We are assessing usage of the current
changes before potentially offering such alternatives.
|
Additional array extensions
There are over 220 added or enhanced extension methods on Object and primitive arrays.
For single dimension arrays, we have: any, chop, collectEntries, column, countBy,
each, eachColumn, eachWithIndex, equals, every, first, flattenMany, head, indexOf,
indexed, init, injectAll, join, last, lastIndexOf, max, maxComparing,
min, minComparing, partitionPoint, putAt, reverse, reverseEach, sort,
sum, tail, toSet, withCollectedKeys, withCollectedValues, withIndex, zip, and zipping.
For multidimensional arrays we have: flatten, transpose, and transposing.
Here are some examples:
int[] nums = -3..2
assert nums.any{ it > 1 }
&& nums.every(n -> n < 4)
&& nums.join(' ') == '-3 -2 -1 0 1 2'
&& nums.head() == -3
&& nums.tail() == -2..2
&& nums.withIndex().take(2)*.join(' ') == ['-3 0', '-2 1']
&& nums.chop(3, 3) == [[-3, -2, -1], [0, 1, 2]]
&& nums.max() == 2
&& nums.max{ it.abs() } == -3
&& nums.reverse() == 2..-3
&& nums.partitionPoint{ it <= 1 } == 5
String[] letters = 'a'..'d'
assert letters.last() == 'd'
&& letters.countBy{ it < 'b' } == [(true):1, (false):3]
&& letters.withIndex()*.join()
== ['a0', 'b1', 'c2', 'd3']
&& letters.indexed().collectEntries{ k, v -> [k, v * k] }
== [0:'', 1:'b', 2:'cc', 3:'ddd']
&& letters.indexed().collectMany{ k, v -> [v] * k }
== ['b', 'c', 'c', 'd', 'd', 'd']
&& letters.withCollectedValues(String::toUpperCase)
== ['a':'A', 'b':'B', 'c':'C', 'd':'D']
&& letters.withCollectedKeys(String::toUpperCase)
== ['A':'a', 'B':'b', 'C':'c', 'D':'d']
&& letters.injectAll('') { carry, next -> carry + next }
== ['a', 'ab', 'abc', 'abcd']
letters[1..2] = 'YZ'.split('')
assert letters == ['a', 'Y', 'Z', 'd']
int[][] matrix = [[1, 2],
[10, 20],
[100, 200]]
assert matrix.transpose() == [[1, 10, 100],
[2, 20, 200]]
assert matrix.flatten() == [1, 2, 10, 20, 100, 200]In some cases, the methods existed for a few of the primitive array types but now work with more. In numerous cases, the functionality was only available by converting the array to a list first - which was easy but increased memory usage and decreased performance. For other cases, implementations now avoid un/boxing where possible. All up this means that Groovy now works better in data science scenarios allowing more streamlined and performant code. Here is one microbenchmark showing the performance of the new array extension methods compared to equivalent Java and Groovy stream operations:
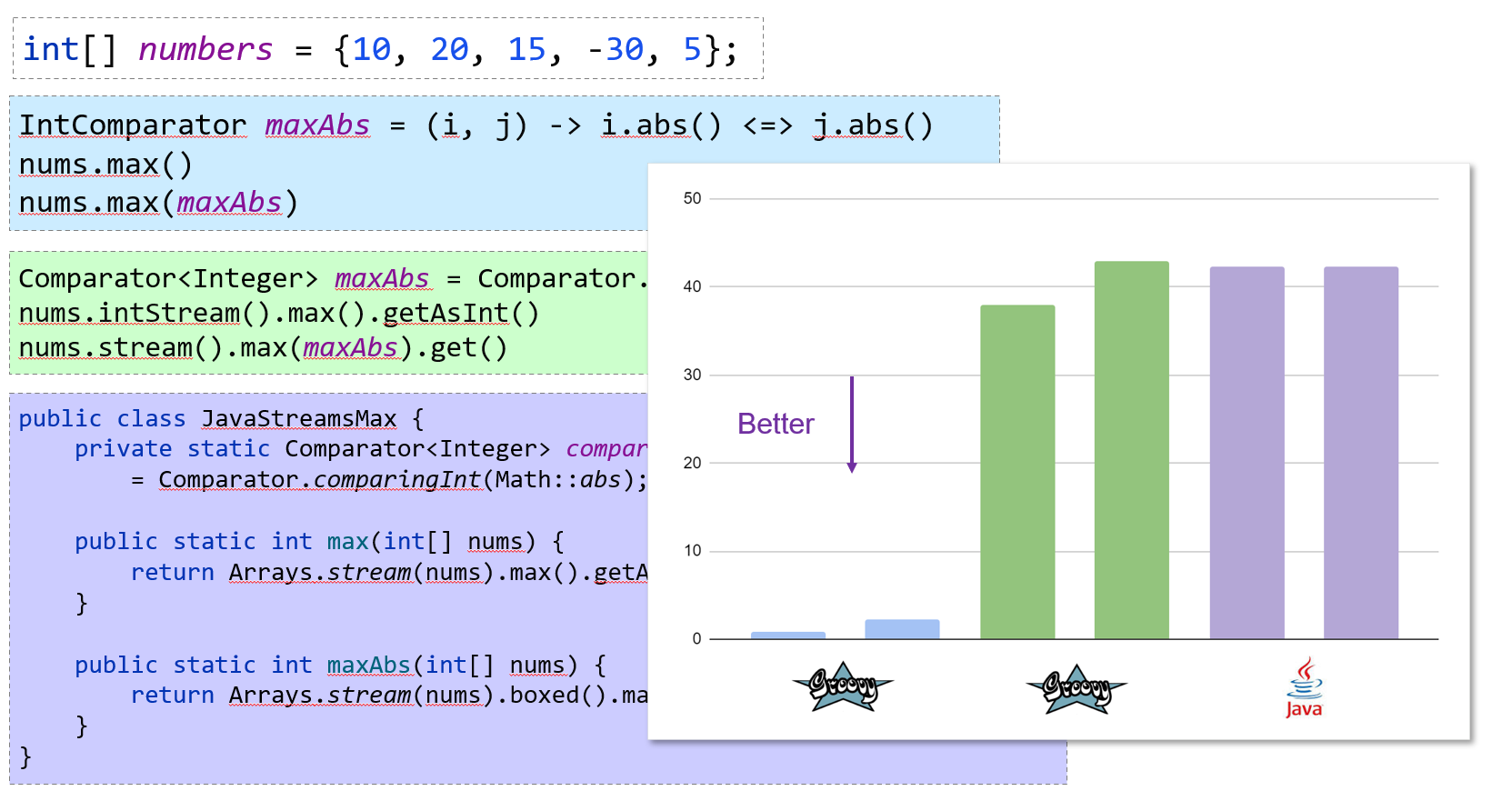
Additional File and Path extensions
There are some additional extension methods for File objects:
def myscript = new File('MyScript.groovy')
assert myscript // Groovy truth: true if the file exists
assert myscript.extension == 'groovy'
assert myscript.baseName == 'MyScript'And similar methods for Path objects:
def mypic = path.resolve('MyFigure.png')
assert mypic // Groovy truth: true if the file exists
assert mypic.extension == 'png'
assert mypic.baseName == 'MyFigure'Additional String extensions
Additional next and previous methods and a codePoints method were added for Strings.
A getLength method was added for StringBuilder and StringBuffer.
These help with simpler String processing in a number of scenarios:
assert (1..3).collect('💙'::next) == ['💚', '💛', '💜']
assert '❤️'.codePoints.size() == 2
assert new StringBuilder('FooBar').tap{ length -= 3 }.toString() == 'Foo'Java compatibility improvements
Multi-dimensional array notation
Groovy uses the curly braces { } syntax when defining closures.
Early versions of Groovy excluded the use of any array literals to avoid conflict with the closure syntax,
and instead piggybacked on the list literal notation. Recent Groovy versions have allowed
single dimension array literals in contexts which are unambiguous. Groovy 5 extends
this to support multidimensional arrays using the Java syntax
(GROOVY-8551).
The existing forms using list notation remain supported.
int[] nums1 = [1, 2, 3]
def nums2 = [1, 2, 3] as int[]
def nums3 = new int[] {1, 2, 3}
int[][] numsA = [[1,2,3] as int[],[4,5,6] as int[]]
int[][] numsB = [[1,2,3],[4,5,6]] // also with static type checking for Groovy 5
def numsC = [[1,2,3],[4,5,6]] as int[][]
def numsD = new int[][] {{1,2,3},{4,5,6}} // added for Groovy 5Pattern Matching for instanceof
JDK16 added support for Pattern Matching for instanceof (JEP 394).
It is intended to allow simplification for code where there is an instanceof test followed by a cast, like this:
if (obj instanceof String) { // Java
String s = (String) obj;
// use s, e.g.
System.out.println(s.toUpperCase());
}Such code can be replaced with the shortened form:
if (obj instanceof String s) { // Java
System.out.println(s.toUpperCase());
}In Groovy, this syntax isn’t needed since the following will work just fine (via duck typing for dynamic Groovy, and type inference when using the static nature):
if (obj instanceof String) {
println obj.toUpperCase()
}But, for improved compatibility with Java, Groovy 5 supports the JEP-394 syntax (GROOVY-10943).
Underscore as a placeholder
The use of "_" (underscore) as a placeholder for unused parameters is earmarked for inclusion in future Java versions (see "Treatment of underscores" in JEP 302: Lambda Leftovers). This is available in Groovy 5 (GROOVY-10943).
Some examples:
// unused components in multi-assignment
var (_, y, m, _, _, d) = Calendar.instance
println "Today is $y-${m+1}-$d" // Today is 2023-8-23
// unused lambda parameters
def c = (_, _, a, b) -> a + b
def d = (_, a, _, b) -> a + b
def e = (_, a, b, _) -> a + b
assert c(1000, 100, 10, 1) == 11
assert d(1000, 100, 10, 1) == 101
assert e(1000, 100, 10, 1) == 110
// unused closure parameters
def f = { a, _, _, b -> a + b }
def g = { a, _, b, _ -> a + b }
def h = { a, b, _, _ -> a + b }
assert f(1000, 100, 10, 1) == 1001
assert g(1000, 100, 10, 1) == 1010
assert h(1000, 100, 10, 1) == 1100Native support for default, private and static methods in interfaces
Earlier versions of Groovy supported the syntax of default methods in interfaces, but implemented them using traits. In Groovy 5, default, private and static methods in interfaces are now supported natively (GROOVY-8299). This improves various integration scenarios with mixed Groovy and Java codebases.
Other improvements
Support for var with multi-assignment
The var keyword can be used in combination with multi-assignment:
var (x, y) = [1, 2]
assert x == 1 && y == 2Support for an index variable in loops
You can now declare an index variable in a for loop definition:
var list = []
var hearts = ['💙', '💚', '💛', '💜']
for (int idx, var heart in hearts) {
idx.times { list << heart }
}
assert list.join() == '💚💛💛💜💜💜'String utility method
There is now a utility method to produce simple ascii-art barcharts. The following code:
[
'Sunday', 'Monday', 'Tuesday',
'Wednesday', 'Thursday',
'Friday', 'Saturday'
].each { day ->
def label = day.padRight(12)
def bar = bar(day.size(), 0, 10, 10)
println "\n$label$bar"
}produces this output:

Breaking changes
-
The return type for the
findIndexValuesextension method for anIteratorwas changed toIteratorfromList. This facilitates calling a series of iterator extension methods in sequence and retaining the inherent lazy nature of the iterator. If you need all index values calculated eagerly, simply add.toList(). If a subsequent extension method is called, no change may be needed. (GROOVY-11647) -
The
chopextension method accepts a sequence of numbers representing sizes of chopped chunks to return. Previous behavior was to return a list for each asked for size including when the chopped collection was fully used, giving one or more empty lists in that case. For other language and libraries offering similar functionality, the common behavior is to stop once the chopped collection is fully used. Groovy 5 now defaults to the common behavior but has an optional boolean to obtain the previous behavior. (GROOVY-11604) -
The return type for the
chopextension method for anIteratorwas changed toIterator<List>fromList<List>. This facilitates calling a series of iterator extension methods in sequence and retaining the inherent lazy nature of the iterator. If you need all chopped lists calculated eagerly, simply add.toList(). If a subsequent extension method is called, no change may be needed. (GROOVY-11599) -
Anonymous inner class visibility was made package-private instead of public to align with Java semantics (GROOVY-11481)
-
There was a breaking change for an edge case involving nulls and the "spread-dot" operator that shouldn’t affect most users (GROOVY-11453)
-
Consistency was improved for Map-based property access with respect to visibility (GROOVY-11403 and GROOVY-11367)
-
Visibility was tightened/aligned for package-private fields, properties and methods (GROOVY-11357)
-
In earlier versions of Groovy, the compiler was lenient when finding duplicate imports or an import and a similarly-named class definition. While having duplicates was considered poor style, the compiler followed the lenient behavior of letting the last definition "win", ignoring earlier definitions. E.g. for two imports (Groovy 1-4):
import java.util.Date import java.sql.Date println Date // => class java.sql.Dateor an import and a class definition (Groovy 1-4):
import java.sql.Date class Date { } println Date // => class Dateor a regular import and an alias import (Groovy 1-4):
import java.util.Date import java.util.Calendar as Date // don't do this! println Date // => class java.util.CalendarFrom Groovy 5, the compiler now follows Java behavior and gives an error in such cases (GROOVY-8254). A slightly more lenient approach is taken when using
groovysh. For thegroovyshrepl, a newly entered import is deemed to override an old import with the same simple name, with the old import being discarded (GROOVY-11224). -
Scripts containing a static
mainmethod and no statements outside that method have changed slightly for improved JEP 512 compatibility. The script class for such methods no longer extendsScriptand hence no longer has access to the script context or bindings. For many such scripts, access to the binding isn’t needed and there is now a simpler structure for those scripts. If you have a script with such a method, convert it to a normal Groovy script, or change it to instead use a no-arg instancerunmethod. (GROOVY-11118) -
The
getPropertymethod allows for getting properties that don’t exist within a class. Previously, static properties from an outer class were given priority over overrides bygetProperty. This is in conflict with the priority given to outer classes in other places. (GROOVY-10985) -
The minus operator for sets in Groovy was subject to an existing JDK bug in the JDK’s
AbstractSet#removeAllmethod. The behavior now conforms with the behavior of the fix being proposed for that bug. If for some strange reason you rely on the buggy behavior, you can use theremoveAllmethod directly rather than theminusoperator (at least until it is fixed in the JDK). (GROOVY-10964) -
Groovy 4 had a
$getLookupmethod used to work around stricter JPMS access requirements. Groovy no longer needs this hook. This method is not normally visible or of use to typical Groovy users but if framework writers are making use of that hook, they should rework their code. (GROOVY-10931) -
Groovy was incorrectly setting a null default value for annotations without a default value. If framework writers have made use of, or coded around the buggy behavior, they may need to rework their code. It might mean simplification by removing a workaround. (GROOVY-10862)
-
Some Groovy AST transform annotations, like
@ToString,@AutoClone, and@Sortablewere givenRUNTIMEretention even though Groovy itself and typical Groovy user behavior never needs access to that annotation at runtime. This was done with a view that perhaps some future tools or framework might be able to use that information in some useful way. We know of no such frameworks or tools, so we have changed the retention toSOURCEto give cleaner class files and reflect Groovy’s use of those annotations. Annotation collectors like@Immutable(RUNTIMEfor legacy reasons), and@Canonical(CLASSfor potential future tooling though not currently stored) are also nowSOURCEretention. (GROOVY-10855) -
Explicit
abstractorfinalmodifiers on an Enum definition were previously ignored but now cause a compilation error. If you have used those modifiers, remove them from your source files. (GROOVY-10811) -
Groovy’s
%operator is called the "remainder" operator. Informally, it is also known as the "mod" operator and indeed, for operator overloading purposes we have historically used themodmethod. While this name is in part just a convention, it can cause some confusion, since for example, theBigIntegerclass has bothremainderandmodmethods and our behavior, like Java’s, follows the behavior of theremaindermethod. In Groovy 5, operator overloading for%is now handled by theremaindermethod. Fallback behavior is supported and workarounds exist for folks already using themodmethod. (GROOVY-10800) -
It is now possible to create a custom class loader that extends
GroovyClassLoaderwhich uses a different cache class for the source cache. Anyone doing this and relying on the specific type for the protectedsourceCachefield should change their code to use theFlexibleEvictableCacheinterface type rather than the previous hard-coded implementation class. (GROOVY-9742) -
Improvements have been made to include additional checking for captured types. (GROOVY-9074)
-
Improvements have been made to better align how method selection is performed between the dynamic Groovy runtime and with static compilation. (GROOVY-8788)
-
Improvements have been made when mixing
@TupleConstructorand traits with default values. (GROOVY-8219, -
Improvements have been made to improve consistency when accessing fields within Map-like classes. (GROOVY-6144, GROOVY-5001)
JDK requirements
Groovy 5 requires JDK17+ to build and JDK11 is the minimum version of the JRE that we support. Groovy 5 has been tested on JDK versions 11 through 25.
More information
You can browse all the tickets closed for Groovy 5.0 in JIRA.